
자바를 공부하다 보면 Collection과 Collections라는 비슷하게 생긴 두 단어를 마주하게 됩니다. 's' 하나 차이인데 역할은 완전히 다릅니다.
Collection 는 데이터를 담는 그릇(Framework)이고, Collections 는 그 그릇을 요리하는 도구(Utility)입니다.
오늘은 자바의 자료구조 전체 지도인 컬렉션 프레임워크를 먼저 훑어보고, 다음 장에 이를 효율적으로 다루기 위한 Collections 클래스의 기능들을 정리해 보겠습니다.
1. 자바 컬렉션 프레임워크 (Collection Framework)
컬렉션 프레임워크란 "다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 클래스의 집합"을 의미합니다.
즉, 자료구조(Data Structure)와 알고리즘을 자바 클래스로 구현해 놓은 것입니다.
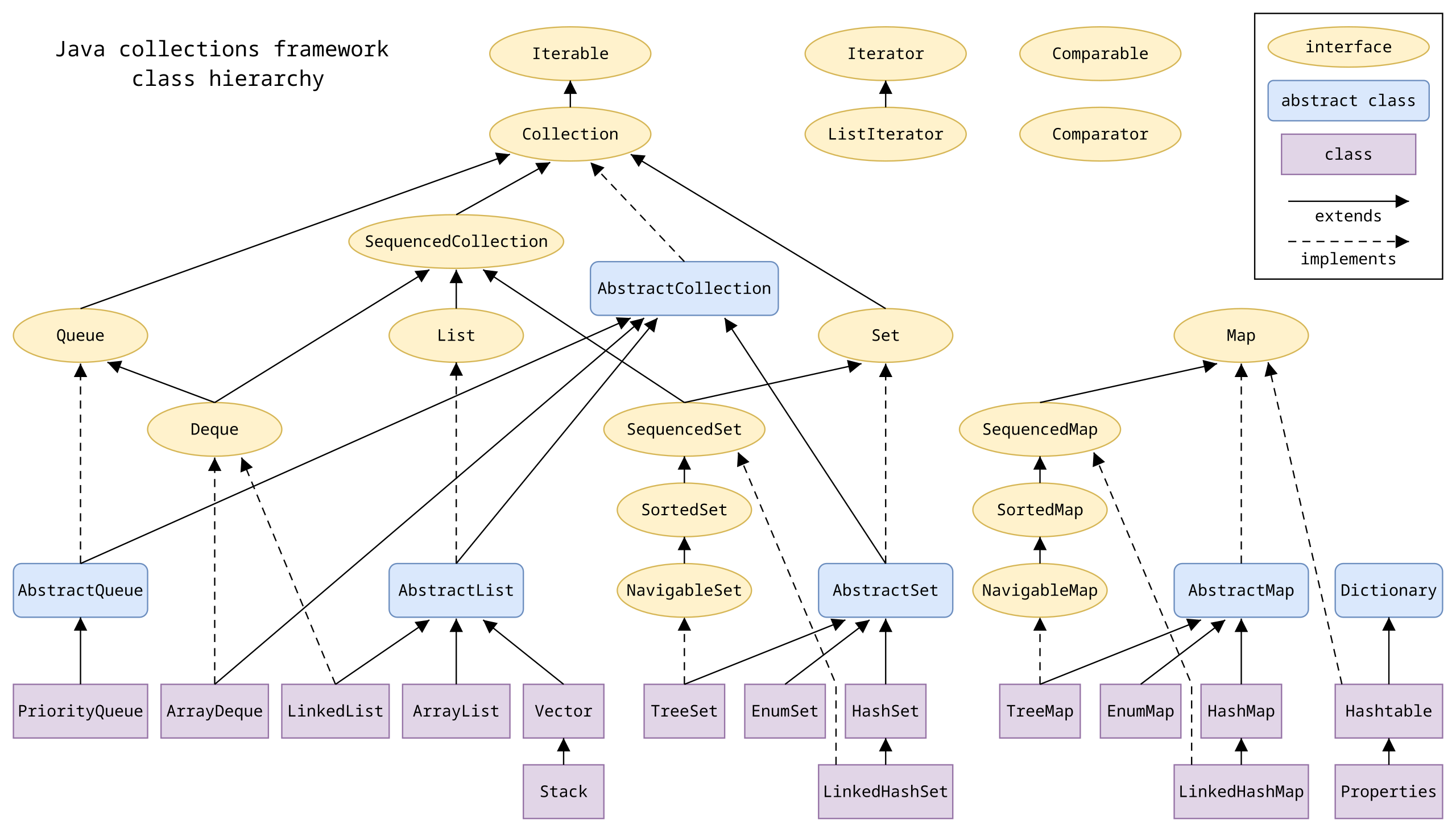
Collection Framework 주요 인터페이스 특징
| 인터페이스 | 특징 | 구현 클래스 |
|---|---|---|
| List | 순서가 있음, 중복 허용 | ArrayList, LinkedList, Stack, Vector |
| Set | 순서가 없음, 중복 불가 | HashSet, TreeSet, LinkedHashSet |
| Map | Key-Value 쌍, Key 중복 불가, 순서 없음 (Collection 인터페이스 상속 아님) |
HashMap, TreeMap, LinkedHashMap, Properties |
| Queue | 선입선출(FIFO) 구조 | LinkedList, PriorityQueue |
2. List 인터페이스 (순서 O, 중복 O)
"줄 서기"와 같습니다. 데이터가 들어온 순서대로 저장되며, 똑같은 데이터가 또 들어와도 상관없습니다.
인덱스(방 번호)를 이용해 데이터를 관리합니다.
| 클래스 | 내부 구조 | 장점 (속도) | 단점 |
|---|---|---|---|
| ArrayList | 동적 배열 (Object[]) | 조회(Get) 빠름 | 중간 삽입/삭제 느림 |
| LinkedList | 노드 연결 (Node<E>) | 중간 삽입/삭제 빠름 | 조회(Get) 느림 |
| Vector | 동적 배열 + 동기화 | 멀티스레드 안전(Safe) | 무겁고 느림 (Legacy) |
- 상세 설명
- ArrayList: 데이터를 순차적으로 추가/조회할 때 성능이 가장 좋습니다. 하지만 중간에 요소를 끼워 넣으려면 뒤에 있는 데이터들을 전부 한 칸씩 밀어야 해서 느립니다.
- LinkedList: 앞뒤 요소의 주소만 알고 연결된 구조입니다. 중간에 데이터를 넣을 때 주소만 바꿔주면 되므로 빠릅니다. 하지만 5번째 데이터를 찾으려면 처음부터 하나씩 건너가야 해서 조회는 느립니다.
- Vector: ArrayList의 옛날 버전입니다.
synchronized가 걸려있어 성능이 떨어지므로, 동기화가 필요하면Collections.synchronizedList()를 쓰는 게 낫습니다.
List<String> list = new ArrayList<>();
list.add("Java");
list.add("Java"); // 중복 가능
list.add(1, "Spring"); // 중간 삽입 (이 경우 LinkedList가 더 유리할 수 있음)
System.out.println(list); // [Java, Spring, Java]3. Set 인터페이스 (순서 X, 중복 X)
"주머니"와 같습니다. 순서가 뒤죽박죽이며, 똑같은 구슬을 두 개 넣을 수 없습니다.
중복 제거가 필요할 때 핵심적으로 사용됩니다.
| 클래스 | 내부 구조 | 정렬/순서 | 특징 |
|---|---|---|---|
| HashSet | Hash Table | 순서 없음 (Random) | 가장 빠름, 일반적인 Set |
| LinkedHashSet | Hash Table + LinkedList | 입력 순서 보장 | 순서가 중요한 경우 사용 |
| TreeSet | Red-Black Tree | 오름차순 정렬 | 범위 검색, 정렬된 데이터 필요 시 |
- 상세 설명
- HashSet:
hashCode()와equals()를 이용해 중복을 걸러냅니다. 순서를 보장하지 않으므로, "데이터가 들어있는지 확인(contains)"하는 용도로 가장 빠르고 좋습니다. - LinkedHashSet: HashSet에 순서 기억 기능을 추가한 것입니다. 데이터가 들어온 순서대로 출력하고 싶을 때 사용합니다.
- TreeSet: 이진 탐색 트리 구조로 데이터를 저장하면서 자동으로 정렬(Sorting)합니다. HashSet보다는 느리지만, "가나다순 출력"이나 "특정 범위 검색"에 유리합니다.
Set<String> set = new HashSet<>();
set.add("Java");
set.add("Java"); // 중복 발생 -> 저장 안 됨 (false 반환)
set.add("Android");
set.add("Spring");
System.out.println(set);
// 출력 결과 예시: [Spring, Java, Android] (순서 보장 안 됨)4. Queue 인터페이스 (선입선출 대기열)
"놀이공원 줄 서기"와 같습니다. 먼저 들어온 데이터가 먼저 나가는 FIFO(First In First Out) 구조입니다. 순서가 있지만, 중간에 새치기(삽입)는 불가능합니다.
| 클래스 | 내부 구조 | 특징 | 활용 |
|---|---|---|---|
| LinkedList | Node 연결 | 큐의 표준 구현체 | 일반적인 큐 작업 |
| PriorityQueue | Heap (이진 트리) | 우선순위 정렬 | 작업 스케줄링 (중요도 순) |
| ArrayDeque | 가변 배열 (Circular) | 양쪽 끝 접근 가능 | 스택/큐 대용 (성능 우수) |
- 상세 설명
- LinkedList: List 인터페이스도 구현하고 Queue 인터페이스도 구현했습니다. 큐로 사용할 때는
offer(넣기),poll(꺼내기)메서드를 주로 사용합니다. - PriorityQueue: 들어온 순서와 상관없이 "우선순위가 높은 데이터"가 먼저 나갑니다. 기본적으로는 숫자가 낮은 것이 우선이며, 생성자에 기준을 설정할 수 있습니다.
- ArrayDeque: 큐(Queue)와 스택(Stack)의 기능을 모두 합친 덱(Deque)의 구현체입니다. 성능이 매우 좋아 실무에서 Stack 대신 많이 쓰입니다.
Queue<String> queue = new LinkedList<>();
queue.offer("첫번째");
queue.offer("두번째");
queue.offer("세번째");
System.out.println(queue.poll()); // "첫번째" (가장 먼저 들어간 것)
System.out.println(queue); // ["두번째", "세번째"]5. Map 인터페이스 (키와 값의 쌍)
Map은 엄밀히 말해 Collection 인터페이스의 자식은 아닙니다. 하지만 프레임워크의 중요한 한 축입니다. Key(키)와 Value(값)의 쌍으로 데이터를 관리합니다.
| 구현 클래스 | Key 특징 | 정렬 | Null 허용 |
|---|---|---|---|
| HashMap | 중복 불가 | 순서 없음 | Key 1개, Value 다수 허용 |
| LinkedHashMap | 중복 불가 | 입력 순서 보장 | 허용 |
| TreeMap | 중복 불가 | Key 기준 오름차순 | Key Null 불가 |
| Hashtable | 중복 불가 | 순서 없음 | Key/Value 둘 다 Null 불가 |
- 상세 설명
- HashMap: 가장 널리 쓰입니다. Key의 중복은 허용하지 않고, Value의 중복은 허용합니다. 순서를 보장하지 않지만 검색 속도가 매우 빠릅니다.
- TreeMap: Key를 기준으로 자동 정렬됩니다. 정렬된 순서대로 조회하거나 범위 검색이 필요할 때 사용합니다.
- Hashtable: HashMap의 구버전(Legacy)입니다. 동기화(Synchronized)가 되어 있어 멀티스레드 환경에서 안전하지만 느립니다. 최근에는
ConcurrentHashMap을 더 권장합니다.
Map<String, Integer> map = new HashMap<>();
map.put("사과", 1000);
map.put("바나나", 2000);
map.put("사과", 1500); // Key 중복! -> 기존 값(1000)이 덮어씌워짐
System.out.println(map.get("사과")); // 15006. Collection Framework 핵심 요약
- 순서가 중요하고 중복 데이터도 저장해야 한다면?
👉 List (ArrayList) - 중복을 제거해야 하고, 존재 여부(Contains) 확인이 중요하다면?
👉 Set (HashSet) - 데이터를 순서대로(선입선출) 처리해야 한다면?
👉 Queue (LinkedList) - ID, 사번처럼 고유한 키(Key)로 데이터를 빠르게 찾아야 한다면?
👉 Map (HashMap)
Tip _ 인터페이스 기반 코딩
변수를 선언할 때는 구체적인 클래스(ArrayList)보다는 인터페이스(List)를 사용하는 습관을 들이는 것이 좋습니다.
❌ Bad: ArrayList<String> list = new ArrayList<>();
⭕ Good: List<String> list = new ArrayList<>();
👉 이렇게 해야 나중에 new LinkedList<>()로 구현체를 바꿔도 나머지 코드를 수정할 필요가 없어집니다. (유연성 증가)
Collection Framework 에 대해 정리를 해보았고 !!
다음으로는 Collections 클래스 에 대해 어떤 메서드들과 기능들이 있는지 정리해 보겠습니다 ~!
'Language > Java' 카테고리의 다른 글
| [JAVA] 인터페이스 vs 추상클래스 차이점 정리 (0) | 2026.01.07 |
|---|---|
| [JAVA] Stack 구현 & Stack Class의 문제점 (feat. Deque) (0) | 2025.12.19 |
| [JAVA] Getter/Setter 이중성 & 문제점 Refactoring (1) | 2025.12.12 |
| [JAVA] 접근제한자 & 캡슐화 (0) | 2025.12.12 |
| [JAVA] 객체 지향 프로그래밍 4대 원칙 (0) | 2025.12.12 |